#. 3 데이터 증강
본 프로젝트에서는 웨이퍼 맵의 클래스 불균형 문제를 완화하기 위해 전통적 증강, 생성형 AI 기반 증강, 하이브리드형 증강, 합성 증강의 네 가지 방식을 비교 가능한 실험군으로 구성했다. 각 방식은 동일한 데이터 불균형 문제를 해결한다는 공통 목적을 가지지만, 결함 패턴을 확장하는 방식과 데이터 구성 철학에서 차이를 둔다.
전통적 증강은 회전과 반전 같은 기하학적 변환을 통해 기존 결함 패턴을 확장하는 방식이며, 생성형 AI 증강은 diffusion 기반 모델을 이용해 부족한 결함 샘플 자체를 새롭게 생성하는 방식이다. 하이브리드형 증강은 이 두 방법을 결합해 전통적 변환의 안정성과 생성형 모델의 다양성을 함께 확보하고자 했다. 합성 증강은 결함 패턴을 None 웨이퍼 위에 삽입하는 방식으로, 이후 탐지 실험까지 고려한 별도의 증강 축으로 설계했다.
이 중 전통적 증강 실험에서는 1개 fold 단위로 클래스별 처리 규칙을 고정하여 데이터셋을 구성했다. 먼저 None 클래스는 결함이 없는 정상 웨이퍼이므로 증강 대상이 아니라 기준 데이터로 취급했다. 따라서 seed를 고정한 뒤 2,000장만 다운샘플링하여 사용하고, 선택되지 않은 나머지 샘플은 이후 합성 증강에서 재사용할 수 있도록 별도의 pkl 파일로 저장했다.
반면 결함 클래스는 모두 증강 대상에 포함했다. 각 결함 클래스에 대해서는 원본 데이터를 전부 유지한 상태에서 회전 및 반전 기반 8배수 증강을 수행해 결함 패턴을 확장했다. 이후 클래스별 총 샘플 수에 따라 두 가지 방식으로 최종 2,000장을 맞췄다.
첫 번째는 증강 이후 총개수가 2,000장 이상인 경우이다. 이 경우에는 원본 데이터를 모두 포함한 뒤, 나머지 필요한 수량만큼만 증강본에서 seed 고정 방식으로 추출하여 최종 개수를 맞췄다. 이렇게 하면 원본 데이터의 정보는 최대한 보존하면서도, 과도한 중복 없이 균형 잡힌 데이터셋을 구성할 수 있다.
두 번째는 증강 이후에도 총개수가 2,000장에 미치지 못하는 경우이다. 이 경우에는 생성된 증강본을 모두 포함한 뒤에도 부족한 수량이 남게 되므로, seed를 고정한 상태에서 중복 허용 재샘플링을 적용해 최종적으로 2,000장을 맞췄다. 특히 Near-full처럼 원본 자체가 매우 적은 클래스에서는 이러한 방식이 필요했으며, 실험 조건을 통일하기 위한 현실적인 보정 전략으로 사용했다.
이와 같은 규칙을 통해 각 fold마다 클래스별 샘플 수를 일정하게 맞추면서도, 단순히 숫자만 맞추는 것이 아니라 원본 보존, 증강 활용, 재현 가능성(seed 고정) 을 함께 확보하고자 했다.
-> 생성형 AI 모델은 Difussion 계열 CFG-DDPM 사용
1. 전통적 증강
import pandas as pd
import numpy as np
import random
import os
def get_traditional_augs(wafer_map):
"""원본 1개로부터 7개의 전통적 증강 이미지 생성"""
augs = []
for k in range(1, 4):
augs.append(np.rot90(wafer_map, k))
flip_ud = np.flipud(wafer_map)
augs.append(flip_ud)
flip_lr = np.fliplr(wafer_map)
augs.append(flip_lr)
augs.append(np.rot90(flip_ud, 1))
augs.append(np.rot90(flip_lr, 1))
return augs
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
DATA_DIR = os.path.abspath(os.path.join(CURRENT_DIR, "../../"))
AUGMENT_DIR = os.path.abspath(os.path.join(CURRENT_DIR, "../"))
print("[Dataset 2 - Cleaned] 전통적 증강 시작 (Seed: 7)")
print(f"데이터 탐색 경로: {DATA_DIR}")
TARGET_COUNT = 2000
SEED_VAL = 7
random.seed(SEED_VAL)
np.random.seed(SEED_VAL)
background_pool = pd.DataFrame()
for i in range(1, 5):
file_name = os.path.join(DATA_DIR, f'dataset_fold_{i}_cleaned.pkl')
if not os.path.exists(file_name):
print(f"{file_name} 파일을 찾을 수 없습니다.")
continue
print(f"\ndataset_fold_{i}_cleaned.pkl 처리 중")
df = pd.read_pickle(file_name)
augmented_rows = []
classes = df['failure_str'].unique()
for cls in classes:
cls_df = df[df['failure_str'] == cls].copy()
originals = cls_df['waferMap'].tolist()
count = len(originals)
# None 클래스는 2000장만 사용하고, 나머지는 배경 풀로 분리
if cls == 'None':
sampled_none = cls_df.sample(n=min(TARGET_COUNT, count), random_state=SEED_VAL)
augmented_rows.append(sampled_none)
leftovers = cls_df.drop(sampled_none.index)
background_pool = pd.concat([background_pool, leftovers], ignore_index=True)
print(f" - [None] {len(sampled_none)}장 추출 완료, {len(leftovers)}장은 배경 풀로 이동")
continue
# 결함 클래스는 2000장을 기준으로 맞춤
print(f" - [{cls}] 원본 {count}장 -> ", end="")
if count >= TARGET_COUNT:
sampled_orig = cls_df.sample(n=TARGET_COUNT, random_state=SEED_VAL)
augmented_rows.append(sampled_orig)
print("원본만으로 2000장 추출 완료")
else:
df_orig = pd.DataFrame({
'waferMap': originals,
'failure_str': [cls] * len(originals)
})
needed = TARGET_COUNT - count
aug_list = []
for wm in originals:
aug_list.extend(get_traditional_augs(wm))
if len(aug_list) >= needed:
selected_augs = random.sample(aug_list, needed)
df_aug = pd.DataFrame({
'waferMap': selected_augs,
'failure_str': [cls] * len(selected_augs)
})
final_cls_df = pd.concat([df_orig, df_aug], ignore_index=True)
augmented_rows.append(final_cls_df)
print("증강본 일부 추출로 2000장 완료")
else:
unique_total = originals + aug_list
still_needed = TARGET_COUNT - len(unique_total)
# 증강본까지 모두 사용해도 부족한 경우 일부를 중복 샘플링
copied_augs = random.choices(unique_total, k=still_needed)
df_unique = pd.DataFrame({
'waferMap': unique_total,
'failure_str': [cls] * len(unique_total)
})
df_copy = pd.DataFrame({
'waferMap': copied_augs,
'failure_str': [cls] * len(copied_augs)
})
final_cls_df = pd.concat([df_unique, df_copy], ignore_index=True)
augmented_rows.append(final_cls_df)
print(f"증강본 전부 사용 후 {still_needed}장 복제로 2000장 완료")
fold_result_df = pd.concat(augmented_rows, ignore_index=True)
fold_result_df = fold_result_df.sample(frac=1, random_state=SEED_VAL).reset_index(drop=True)
save_path = os.path.join(CURRENT_DIR, f'dataset2_fold_{i}_aug_cleaned.pkl')
fold_result_df.to_pickle(save_path)
print(f"{save_path} 저장 완료")
# 남은 None 데이터를 합성용 배경 풀로 저장
bg_pool_path = os.path.join(AUGMENT_DIR, 'background_pool_cleaned.pkl')
background_pool.to_pickle(bg_pool_path)
print(f"\n모든 처리 완료. 배경 풀 저장 경로: {bg_pool_path}")
본 코드는 cleaned 웨이퍼맵 데이터셋에 대해 fold 단위 전통적 증강을 수행한다. 각 fold의 클래스 분포를 확인한 뒤, None 클래스는 과도한 비율을 방지하기 위해 2000장만 샘플링하고, 남은 데이터는 추후 결함 합성용 배경 풀로 분리 저장한다. 결함 클래스에 대해서는 90°, 180°, 270° 회전, 상하 반전, 좌우 반전 등 구조적 의미를 크게 훼손하지 않는 변환을 적용하여 증강 이미지를 생성한다. 클래스별 최종 데이터 수는 2000장을 기준으로 맞추며, 증강본만으로 부족한 경우에는 원본 및 증강본을 포함한 데이터에서 일부를 중복 샘플링하여 수량을 보정한다. 최종적으로 각 fold별 증강 데이터셋과 배경 풀을 별도의 pickle 파일로 저장한다.
2. 생성형 AI 증강(CFG-DDPM)
생성형 AI 방식은 전통적 증강처럼 회전이나 반전으로 기존 샘플을 변형하는 방식이 아니라, 학습된 확산 모델이 결함 패턴을 직접 생성한다는 점에서 차이가 있다. 따라서 이 실험에서는 결함 클래스에 대해 회전/반전 증강을 사용하지 않고, 원본 데이터를 모두 포함한 뒤 부족한 수량만큼만 생성본으로 보충했다.
반면 None 클래스는 생성 대상에서 제외했다. None은 정상 웨이퍼이므로 생성형 증강보다는 구조 유지와 비교 기준의 역할이 더 중요하다고 판단했다. 이에 따라 seed를 고정해 2,000장만 다운샘플링하고, 남은 데이터는 별도로 분리해 이후 합성 데이터 실험에서 background pool로 재사용할 수 있도록 구성했다. 또한 추후 탐지 실험으로 확장할 가능성을 고려해 모든 데이터는 이미지 파일이 아닌 64×64 raw array(0/1/2 값) 형태 그대로 저장했다.
구현은 세 개의 파일로 나누어 진행했다.
# ddpm_model.py
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
# ---------------------------
# 0/1/2 <-> -1/0/1 변환
# ---------------------------
def encode_wafer(x: torch.Tensor) -> torch.Tensor:
"""
입력: 0,1,2 값을 가지는 텐서
출력: -1,0,1 값을 가지는 float 텐서
"""
x = x.float()
out = x.clone()
out[x == 0] = -1.0
out[x == 1] = 0.0
out[x == 2] = 1.0
return out
def decode_wafer(x: torch.Tensor) -> torch.Tensor:
"""
입력: 연속값 텐서
출력: 0,1,2 정수 텐서
기준:
x < -0.5 -> 0
-0.5 <= x < 0.5 -> 1
x >= 0.5 -> 2
"""
out = torch.zeros_like(x, dtype=torch.long)
out[(x >= -0.5) & (x < 0.5)] = 1
out[x >= 0.5] = 2
return out
def build_circular_mask(size: int = 64, radius_ratio: float = 0.48, device=None) -> torch.Tensor:
"""
64x64 웨이퍼용 원형 마스크 생성
radius_ratio는 이미지 크기 대비 반지름 비율
"""
yy, xx = torch.meshgrid(
torch.arange(size, device=device),
torch.arange(size, device=device),
indexing="ij"
)
center = (size - 1) / 2.0
radius = size * radius_ratio
dist = torch.sqrt((yy - center) ** 2 + (xx - center) ** 2)
mask = (dist <= radius).float()
return mask # [H, W]
def apply_wafer_mask(x: torch.Tensor, mask: torch.Tensor, fill_value: float = -1.0) -> torch.Tensor:
"""
x: [B,1,H,W] 또는 [1,H,W] 또는 [H,W]
mask 바깥은 fill_value로 채움
"""
while mask.dim() < x.dim():
mask = mask.unsqueeze(0)
return x * mask + fill_value * (1.0 - mask)
# ---------------------------
# Timestep Embedding
# ---------------------------
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim: int):
super().__init__()
self.dim = dim
def forward(self, t: torch.Tensor) -> torch.Tensor:
"""
t: [B]
return: [B, dim]
"""
device = t.device
half_dim = self.dim // 2
emb_scale = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb_scale)
emb = t[:, None].float() * emb[None, :]
emb = torch.cat([emb.sin(), emb.cos()], dim=-1)
return emb
# ---------------------------
# Basic Blocks
# ---------------------------
class ResidualBlock(nn.Module):
def __init__(self, in_ch: int, out_ch: int, emb_dim: int):
super().__init__()
self.conv1 = nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_ch, out_ch, kernel_size=3, padding=1)
self.norm1 = nn.GroupNorm(8, out_ch)
self.norm2 = nn.GroupNorm(8, out_ch)
self.act = nn.SiLU()
self.emb_proj = nn.Linear(emb_dim, out_ch)
self.skip = nn.Conv2d(in_ch, out_ch, kernel_size=1) if in_ch != out_ch else nn.Identity()
def forward(self, x: torch.Tensor, emb: torch.Tensor) -> torch.Tensor:
h = self.conv1(x)
h = self.norm1(h)
h = self.act(h)
emb_out = self.emb_proj(emb).unsqueeze(-1).unsqueeze(-1)
h = h + emb_out
h = self.conv2(h)
h = self.norm2(h)
h = self.act(h)
return h + self.skip(x)
class DownBlock(nn.Module):
def __init__(self, in_ch: int, out_ch: int, emb_dim: int):
super().__init__()
self.res = ResidualBlock(in_ch, out_ch, emb_dim)
self.down = nn.Conv2d(out_ch, out_ch, kernel_size=4, stride=2, padding=1)
def forward(self, x: torch.Tensor, emb: torch.Tensor):
x = self.res(x, emb)
skip = x
x = self.down(x)
return x, skip
class UpBlock(nn.Module):
def __init__(self, in_ch: int, skip_ch: int, out_ch: int, emb_dim: int):
super().__init__()
self.up = nn.ConvTranspose2d(in_ch, out_ch, kernel_size=4, stride=2, padding=1)
self.res = ResidualBlock(out_ch + skip_ch, out_ch, emb_dim)
def forward(self, x: torch.Tensor, skip: torch.Tensor, emb: torch.Tensor):
x = self.up(x)
x = torch.cat([x, skip], dim=1)
x = self.res(x, emb)
return x
# ---------------------------
# Conditional U-Net
# ---------------------------
class ConditionalUNet(nn.Module):
def __init__(
self,
in_channels: int = 1,
base_channels: int = 64,
num_classes: int = 10,
time_emb_dim: int = 128,
class_emb_dim: int = 128
):
super().__init__()
self.time_mlp = nn.Sequential(
SinusoidalPosEmb(time_emb_dim),
nn.Linear(time_emb_dim, time_emb_dim),
nn.SiLU(),
nn.Linear(time_emb_dim, time_emb_dim),
)
self.class_emb = nn.Embedding(num_classes, class_emb_dim)
self.cond_proj = nn.Sequential(
nn.Linear(time_emb_dim + class_emb_dim, time_emb_dim),
nn.SiLU(),
nn.Linear(time_emb_dim, time_emb_dim),
)
self.input_conv = nn.Conv2d(in_channels, base_channels, kernel_size=3, padding=1)
self.down1 = DownBlock(base_channels, base_channels, time_emb_dim) # 64 -> 32
self.down2 = DownBlock(base_channels, base_channels * 2, time_emb_dim) # 32 -> 16
self.down3 = DownBlock(base_channels * 2, base_channels * 4, time_emb_dim) # 16 -> 8
self.mid1 = ResidualBlock(base_channels * 4, base_channels * 4, time_emb_dim)
self.mid2 = ResidualBlock(base_channels * 4, base_channels * 4, time_emb_dim)
self.up3 = UpBlock(base_channels * 4, base_channels * 4, base_channels * 2, time_emb_dim)
self.up2 = UpBlock(base_channels * 2, base_channels * 2, base_channels, time_emb_dim)
self.up1 = UpBlock(base_channels, base_channels, base_channels, time_emb_dim)
self.out_norm = nn.GroupNorm(8, base_channels)
self.out_act = nn.SiLU()
self.out_conv = nn.Conv2d(base_channels, in_channels, kernel_size=3, padding=1)
def forward(self, x: torch.Tensor, t: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
t_emb = self.time_mlp(t)
c_emb = self.class_emb(y)
emb = self.cond_proj(torch.cat([t_emb, c_emb], dim=-1))
x = self.input_conv(x)
x, skip1 = self.down1(x, emb)
x, skip2 = self.down2(x, emb)
x, skip3 = self.down3(x, emb)
x = self.mid1(x, emb)
x = self.mid2(x, emb)
x = self.up3(x, skip3, emb)
x = self.up2(x, skip2, emb)
x = self.up1(x, skip1, emb)
x = self.out_norm(x)
x = self.out_act(x)
x = self.out_conv(x)
return x
# ---------------------------
# Diffusion
# ---------------------------
class GaussianDiffusion:
def __init__(
self,
model: nn.Module,
image_size: int = 64,
timesteps: int = 1000,
beta_start: float = 1e-4,
beta_end: float = 2e-2,
device: str = "cuda"
):
self.model = model
self.image_size = image_size
self.timesteps = timesteps
self.device = device
betas = torch.linspace(beta_start, beta_end, timesteps, device=device)
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
self.betas = betas
self.alphas = alphas
self.alphas_cumprod = alphas_cumprod
self.alphas_cumprod_prev = alphas_cumprod_prev
self.sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - alphas_cumprod)
self.sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
self.posterior_variance = betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod)
def _extract(self, a: torch.Tensor, t: torch.Tensor, x_shape):
batch_size = t.shape[0]
out = a.gather(-1, t).reshape(batch_size, *((1,) * (len(x_shape) - 1)))
return out
def q_sample(self, x_start: torch.Tensor, t: torch.Tensor, noise: torch.Tensor = None):
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = self._extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
def p_losses(self, x_start: torch.Tensor, t: torch.Tensor, y: torch.Tensor, noise: torch.Tensor = None):
if noise is None:
noise = torch.randn_like(x_start)
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
noise_pred = self.model(x_noisy, t, y)
loss = F.mse_loss(noise_pred, noise)
return loss
@torch.no_grad()
def p_sample(self, x: torch.Tensor, t: torch.Tensor, y: torch.Tensor, guidance_scale: float = 3.0):
betas_t = self._extract(self.betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = self._extract(self.sqrt_one_minus_alphas_cumprod, t, x.shape)
sqrt_recip_alphas_t = self._extract(self.sqrt_recip_alphas, t, x.shape)
y_null = torch.full_like(y, 9)
eps_cond = self.model(x, t, y)
eps_uncond = self.model(x, t, y_null)
eps = eps_uncond + guidance_scale * (eps_cond - eps_uncond)
model_mean = sqrt_recip_alphas_t * (x - betas_t * eps / sqrt_one_minus_alphas_cumprod_t)
posterior_variance_t = self._extract(self.posterior_variance, t, x.shape)
nonzero_mask = (t != 0).float().reshape(x.shape[0], *((1,) * (len(x.shape) - 1)))
noise = torch.randn_like(x)
return model_mean + nonzero_mask * torch.sqrt(posterior_variance_t) * noise
@torch.no_grad()
def sample(self, y: torch.Tensor, batch_size: int, guidance_scale: float = 3.0):
x = torch.randn((batch_size, 1, self.image_size, self.image_size), device=self.device)
for i in reversed(range(self.timesteps)):
t = torch.full((batch_size,), i, device=self.device, dtype=torch.long)
x = self.p_sample(x, t, y, guidance_scale=guidance_scale)
return x
ddpm_model.py에서는 U-Net 기반 diffusion 구조, 클래스 조건 임베딩, CFG 구조, timestep 규칙, 정규화 및 역정규화 함수를 정의했다.
# train_ddpm.py
import os
import argparse
import random
import numpy as np
import pandas as pd
from collections import Counter
import torch
from torch.utils.data import Dataset, DataLoader
from ddpm_model import ConditionalUNet, GaussianDiffusion, encode_wafer
LABEL_MAP = {
"Center": 0,
"Donut": 1,
"Edge-Loc": 2,
"Edge-Ring": 3,
"Loc": 4,
"Near-full": 5,
"Random": 6,
"Scratch": 7,
"None": 8,
"null": 9,
}
DEFECT_CLASSES = [
"Center",
"Donut",
"Edge-Loc",
"Edge-Ring",
"Loc",
"Near-full",
"Random",
"Scratch",
]
def set_seed(seed: int):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
class WaferDDPMDataset(Dataset):
def __init__(self, df: pd.DataFrame):
self.df = df.reset_index(drop=True)
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
wafer = np.array(row["waferMap"], dtype=np.int64)
label_str = row["failure_str"]
x = torch.tensor(wafer, dtype=torch.float32) # [H, W]
x = encode_wafer(x) # 0/1/2 -> -1/0/1
x = x.unsqueeze(0) # [1, H, W]
y = torch.tensor(LABEL_MAP[label_str], dtype=torch.long)
return x, y
def load_fold_dataframe(data_dir: str, fold: int) -> pd.DataFrame:
file_path = os.path.join(data_dir, f"dataset_fold_{fold}_cleaned.pkl")
if not os.path.exists(file_path):
raise FileNotFoundError(f"파일을 찾을 수 없습니다: {file_path}")
df = pd.read_pickle(file_path)
required_cols = {"waferMap", "failure_str"}
if not required_cols.issubset(df.columns):
raise ValueError(
f"필수 컬럼이 없습니다. 현재 컬럼: {list(df.columns)} / 필요 컬럼: {required_cols}"
)
return df
def filter_defect_classes(df: pd.DataFrame) -> pd.DataFrame:
df = df[df["failure_str"].isin(DEFECT_CLASSES)].copy()
df = df.reset_index(drop=True)
return df
def print_class_distribution(df: pd.DataFrame):
counts = Counter(df["failure_str"].tolist())
print("학습 클래스 분포:")
for cls in DEFECT_CLASSES:
print(f" {cls:10s}: {counts.get(cls, 0)}")
def save_checkpoint(save_path: str, model, optimizer, epoch: int, config: dict):
ckpt = {
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch,
"config": config,
"label_map": LABEL_MAP,
}
torch.save(ckpt, save_path)
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--fold", type=int, required=True, choices=[1, 2, 3, 4])
parser.add_argument("--data_dir", type=str, default=".")
parser.add_argument("--save_dir", type=str, default="./weights")
parser.add_argument("--epochs", type=int, default=50)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--lr", type=float, default=1e-4)
parser.add_argument("--timesteps", type=int, default=1000)
parser.add_argument("--seed", type=int, default=7)
parser.add_argument("--num_workers", type=int, default=0)
parser.add_argument("--null_prob", type=float, default=0.1)
parser.add_argument("--base_channels", type=int, default=64)
parser.add_argument("--time_emb_dim", type=int, default=128)
parser.add_argument("--class_emb_dim", type=int, default=128)
args = parser.parse_args()
set_seed(args.seed)
device = "cuda" if torch.cuda.is_available() else "cpu"
os.makedirs(args.save_dir, exist_ok=True)
print(f"device: {device}")
print(f"fold: {args.fold}")
print(f"seed: {args.seed}")
df = load_fold_dataframe(args.data_dir, args.fold)
df = filter_defect_classes(df)
if len(df) == 0:
raise ValueError("결함 클래스 데이터가 비어 있습니다.")
print(f"총 학습 샘플 수: {len(df)}")
print_class_distribution(df)
dataset = WaferDDPMDataset(df)
dataloader = DataLoader(
dataset,
batch_size=args.batch_size,
shuffle=True,
drop_last=True,
num_workers=args.num_workers,
pin_memory=torch.cuda.is_available(),
)
model = ConditionalUNet(
in_channels=1,
base_channels=args.base_channels,
num_classes=10,
time_emb_dim=args.time_emb_dim,
class_emb_dim=args.class_emb_dim,
).to(device)
diffusion = GaussianDiffusion(
model=model,
image_size=64,
timesteps=args.timesteps,
device=device,
)
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr)
config = {
"fold": args.fold,
"epochs": args.epochs,
"batch_size": args.batch_size,
"lr": args.lr,
"timesteps": args.timesteps,
"seed": args.seed,
"null_prob": args.null_prob,
"base_channels": args.base_channels,
"time_emb_dim": args.time_emb_dim,
"class_emb_dim": args.class_emb_dim,
"device": device,
"data_type": "cleaned",
"train_classes": DEFECT_CLASSES,
}
print("학습 시작")
print(f"batch_size: {args.batch_size}")
print(f"epochs: {args.epochs}")
print(f"lr: {args.lr}")
print(f"timesteps: {args.timesteps}")
print(f"null_prob: {args.null_prob}")
model.train()
for epoch in range(1, args.epochs + 1):
epoch_loss = 0.0
for x, y in dataloader:
x = x.to(device) # [B,1,64,64]
y = y.to(device) # [B]
t = torch.randint(
low=0,
high=args.timesteps,
size=(x.size(0),),
device=device,
dtype=torch.long,
)
y_cond = y.clone()
null_mask = torch.rand(y.size(0), device=device) < args.null_prob
y_cond[null_mask] = LABEL_MAP["null"]
loss = diffusion.p_losses(x_start=x, t=t, y=y_cond)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
print(f"[Fold {args.fold}] Epoch {epoch:03d}/{args.epochs} | loss: {avg_loss:.6f}")
save_path = os.path.join(args.save_dir, f"ddpm_fold_{args.fold}_cleaned.pth")
save_checkpoint(
save_path=save_path,
model=model,
optimizer=optimizer,
epoch=args.epochs,
config=config,
)
print(f"학습 완료")
print(f"가중치 저장 경로: {save_path}")
if __name__ == "__main__":
main()
train_ddpm.py에서는 cleaned fold 데이터를 불러와 결함 클래스 중심으로 모델을 학습하고, fold별 가중치를 .pth 파일로 저장했다. 이때 데이터 누수를 막기 위해 train 데이터만 사용하고 validation/test는 학습에 사용하지 않았다.
# dataSet2.py
import os
import argparse
import random
import pickle
import inspect
import numpy as np
import pandas as pd
import torch
from ddpm_model import ConditionalUNet, GaussianDiffusion
SEED = 7
TARGET_PER_CLASS = 2000
IMG_SIZE = 64
DEFECT_LABELS = {
0: "Center",
1: "Donut",
2: "Edge-Loc",
3: "Edge-Ring",
4: "Loc",
5: "Near-full",
6: "Random",
7: "Scratch",
8: "none",
}
NAME_TO_ID = {v: k for k, v in DEFECT_LABELS.items()}
def set_seed(seed=SEED):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
def load_pkl(path):
with open(path, "rb") as f:
return pickle.load(f)
def save_pkl(obj, path):
with open(path, "wb") as f:
pickle.dump(obj, f)
def to_dataframe(data):
if isinstance(data, pd.DataFrame):
return data.copy()
elif isinstance(data, list):
return pd.DataFrame(data)
else:
raise ValueError("지원하지 않는 pkl 형식입니다. DataFrame 또는 list of dicts 여야 합니다.")
def detect_columns(df):
wafer_col = None
label_col = None
for c in df.columns:
if c in ["waferMap", "wafer_map", "map", "image"]:
wafer_col = c
break
for c in df.columns:
if c in ["failure_num", "failureNum", "label", "class", "target", "failure_label"]:
label_col = c
break
if wafer_col is None:
raise ValueError(f"wafer map 컬럼을 찾지 못했습니다. 현재 컬럼: {list(df.columns)}")
if label_col is None:
raise ValueError(f"label 컬럼을 찾지 못했습니다. 현재 컬럼: {list(df.columns)}")
return wafer_col, label_col
def normalize_label_value(x):
if isinstance(x, str):
x = x.strip()
if x in NAME_TO_ID:
return NAME_TO_ID[x]
if x.lower() == "none":
return 8
raise ValueError(f"알 수 없는 문자열 라벨: {x}")
return int(x)
def apply_circle_mask(arr):
h, w = arr.shape
cy, cx = h // 2, w // 2
radius = min(h, w) // 2
yy, xx = np.ogrid[:h, :w]
mask = (yy - cy) ** 2 + (xx - cx) ** 2 <= radius ** 2
out = np.ones((h, w), dtype=np.uint8)
out[mask] = arr[mask]
return out
def quantize_to_012(x):
"""
x < -0.5 -> 0
-0.5 <= x < 0.5 -> 1
x >= 0.5 -> 2
"""
out = np.zeros_like(x, dtype=np.uint8)
out[(x >= -0.5) & (x < 0.5)] = 1
out[x >= 0.5] = 2
return out
def filter_valid_defect(arr):
return np.any(arr == 2)
def sample_none_class(df, label_col):
none_df = df[df[label_col] == 8].copy()
if len(none_df) < TARGET_PER_CLASS:
sampled = none_df.sample(n=TARGET_PER_CLASS, replace=True, random_state=SEED)
else:
sampled = none_df.sample(n=TARGET_PER_CLASS, replace=False, random_state=SEED)
return sampled.reset_index(drop=True)
def sample_defect_class_if_over(df_cls):
if len(df_cls) > TARGET_PER_CLASS:
return df_cls.sample(n=TARGET_PER_CLASS, replace=False, random_state=SEED).reset_index(drop=True)
return df_cls.reset_index(drop=True)
def build_model_and_diffusion(device):
model = ConditionalUNet(
in_channels=1,
base_channels=64,
num_classes=10,
time_emb_dim=128
).to(device)
init_sig = inspect.signature(GaussianDiffusion.__init__)
init_params = init_sig.parameters
kwargs = {}
if "model" in init_params:
kwargs["model"] = model
if "timesteps" in init_params:
kwargs["timesteps"] = 1000
if "device" in init_params:
kwargs["device"] = device
diffusion = GaussianDiffusion(**kwargs)
return model, diffusion
def load_checkpoint(weight_path, model, device):
ckpt = torch.load(weight_path, map_location=device)
if isinstance(ckpt, dict) and "model_state_dict" in ckpt:
model.load_state_dict(ckpt["model_state_dict"])
else:
model.load_state_dict(ckpt)
model.eval()
return model
def call_sample_adaptively(diffusion, cur_bs, y, class_id, device):
"""
ddpm_model.py의 sample 시그니처에 맞춰 최대한 자동 대응
"""
sig = inspect.signature(diffusion.sample)
params = sig.parameters
kwargs = {}
# batch 크기 관련
if "n" in params:
kwargs["n"] = cur_bs
elif "batch_size" in params:
kwargs["batch_size"] = cur_bs
elif "num_samples" in params:
kwargs["num_samples"] = cur_bs
elif "samples" in params:
kwargs["samples"] = cur_bs
# 라벨 관련
if "labels" in params:
kwargs["labels"] = y
elif "y" in params:
kwargs["y"] = y
elif "classes" in params:
kwargs["classes"] = y
elif "class_labels" in params:
kwargs["class_labels"] = y
elif "cond" in params:
kwargs["cond"] = y
elif "label" in params:
kwargs["label"] = y
elif "class_id" in params:
kwargs["class_id"] = class_id
# shape / size 관련
if "shape" in params:
kwargs["shape"] = (1, IMG_SIZE, IMG_SIZE)
if "img_size" in params:
kwargs["img_size"] = IMG_SIZE
if "image_size" in params:
kwargs["image_size"] = IMG_SIZE
# guidance 관련
if "cfg_scale" in params:
kwargs["cfg_scale"] = 3.0
elif "guidance_scale" in params:
kwargs["guidance_scale"] = 3.0
print(f" sample() 시그니처: {sig}")
print(f" sample() 호출 kwargs: {list(kwargs.keys())}")
return diffusion.sample(**kwargs)
@torch.no_grad()
def generate_for_class(model, diffusion, class_id, n_samples, device, batch_size=64):
generated = []
while len(generated) < n_samples:
cur_bs = min(batch_size, n_samples - len(generated))
y = torch.full((cur_bs,), class_id, dtype=torch.long, device=device)
x = call_sample_adaptively(diffusion, cur_bs, y, class_id, device)
if isinstance(x, tuple):
x = x[0]
if not isinstance(x, torch.Tensor):
x = torch.tensor(x, device=device)
# 가능한 shape들 정리
# (B,1,64,64) 또는 (B,64,64) 기대
if x.ndim == 4 and x.shape[1] == 1:
x = x.squeeze(1)
elif x.ndim == 3:
pass
else:
raise ValueError(f"sample() 반환 shape가 예상과 다릅니다: {tuple(x.shape)}")
x = x.detach().cpu().numpy()
x = quantize_to_012(x)
valid_count_before = len(generated)
for arr in x:
arr = apply_circle_mask(arr)
if filter_valid_defect(arr):
generated.append(arr)
valid_added = len(generated) - valid_count_before
print(f" 생성 시도 {cur_bs}장 -> 유효 샘플 {valid_added}장, 누적 {len(generated)}/{n_samples}")
generated = np.stack(generated[:n_samples], axis=0)
return generated
def make_generated_df(arrs, wafer_col, label_col, class_id):
rows = []
for arr in arrs:
rows.append({
wafer_col: arr.astype(np.uint8),
label_col: class_id
})
return pd.DataFrame(rows)
def build_dataset_for_fold(fold_path, weight_path, output_path, device="cpu"):
print(f"[1] fold 데이터 로드: {fold_path}")
raw = load_pkl(fold_path)
df = to_dataframe(raw)
wafer_col, label_col = detect_columns(df)
print(f" wafer_col = {wafer_col}")
print(f" label_col = {label_col}")
df[label_col] = df[label_col].apply(normalize_label_value)
print("[2] None 클래스 2000장 샘플링")
result_parts = []
none_sampled = sample_none_class(df, label_col)
result_parts.append(none_sampled)
print(f"[3] 모델 로드: {weight_path}")
model, diffusion = build_model_and_diffusion(device)
model = load_checkpoint(weight_path, model, device)
for class_id in range(8):
class_name = DEFECT_LABELS[class_id]
df_cls = df[df[label_col] == class_id].copy().reset_index(drop=True)
n_orig = len(df_cls)
print(f"\n[class {class_id} - {class_name}] 원본 개수: {n_orig}")
if n_orig >= TARGET_PER_CLASS:
sampled = sample_defect_class_if_over(df_cls)
result_parts.append(sampled)
print(f" 원본이 2000장 이상이라 샘플링만 수행 -> {len(sampled)}장")
else:
shortage = TARGET_PER_CLASS - n_orig
print(f" 부족분 생성 필요 -> {shortage}장")
gen_arrs = generate_for_class(
model=model,
diffusion=diffusion,
class_id=class_id,
n_samples=shortage,
device=device,
batch_size=64
)
gen_df = make_generated_df(gen_arrs, wafer_col, label_col, class_id)
merged = pd.concat([df_cls, gen_df], ignore_index=True)
result_parts.append(merged)
print(f" 원본 {n_orig} + 생성 {len(gen_df)} = {len(merged)}장")
final_df = pd.concat(result_parts, ignore_index=True)
print("\n[4] 최종 클래스 분포")
counts = final_df[label_col].value_counts().sort_index()
for k, v in counts.items():
print(f" {DEFECT_LABELS[int(k)]:10s}: {v}")
print(f"\n[5] 저장: {output_path}")
os.makedirs(os.path.dirname(output_path), exist_ok=True)
save_pkl(final_df, output_path)
print("완료")
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--fold", type=int, required=True, help="1~4")
parser.add_argument("--data_dir", type=str, default=".")
parser.add_argument("--weight_dir", type=str, default="./weights")
parser.add_argument("--output_dir", type=str, default="./generated_datasets")
parser.add_argument("--device", type=str, default="cpu")
args = parser.parse_args()
set_seed(SEED)
fold_path = os.path.join(args.data_dir, f"dataset_fold_{args.fold}_cleaned.pkl")
weight_path = os.path.join(args.weight_dir, f"ddpm_fold_{args.fold}_cleaned.pth")
output_path = os.path.join(args.output_dir, f"dataset2_fold_{args.fold}_ai_cleaned.pkl")
build_dataset_for_fold(
fold_path=fold_path,
weight_path=weight_path,
output_path=output_path,
device=args.device
)
if __name__ == "__main__":
main()
마지막으로 dataSet2.py에서는 각 클래스별 부족 수량을 계산한 뒤, 저장된 DDPM 가중치를 불러와 필요한 개수만큼 샘플을 생성하고, 이를 원본과 합쳐 최종 fold별 pkl 데이터셋으로 저장했다.
생성 결과는 바로 저장하지 않고 몇 가지 후처리를 거쳤다. 먼저 diffusion 모델의 연속값 출력을 다시 0/1/2 정수값으로 양자화해 원래 웨이퍼 맵 구조에 맞도록 복원했다. 이후 웨이퍼 외곽의 불필요한 노이즈를 제거하기 위해 원형 마스크를 적용했고, 최종 결과는 이미지가 아닌 raw array 상태로 유지했다. 이 과정을 통해 생성형 AI 증강 데이터셋은 분류 실험에 바로 사용할 수 있을 뿐 아니라, 이후 bbox 추출이나 탐지 데이터셋 전환에도 활용할 수 있도록 설계했다.
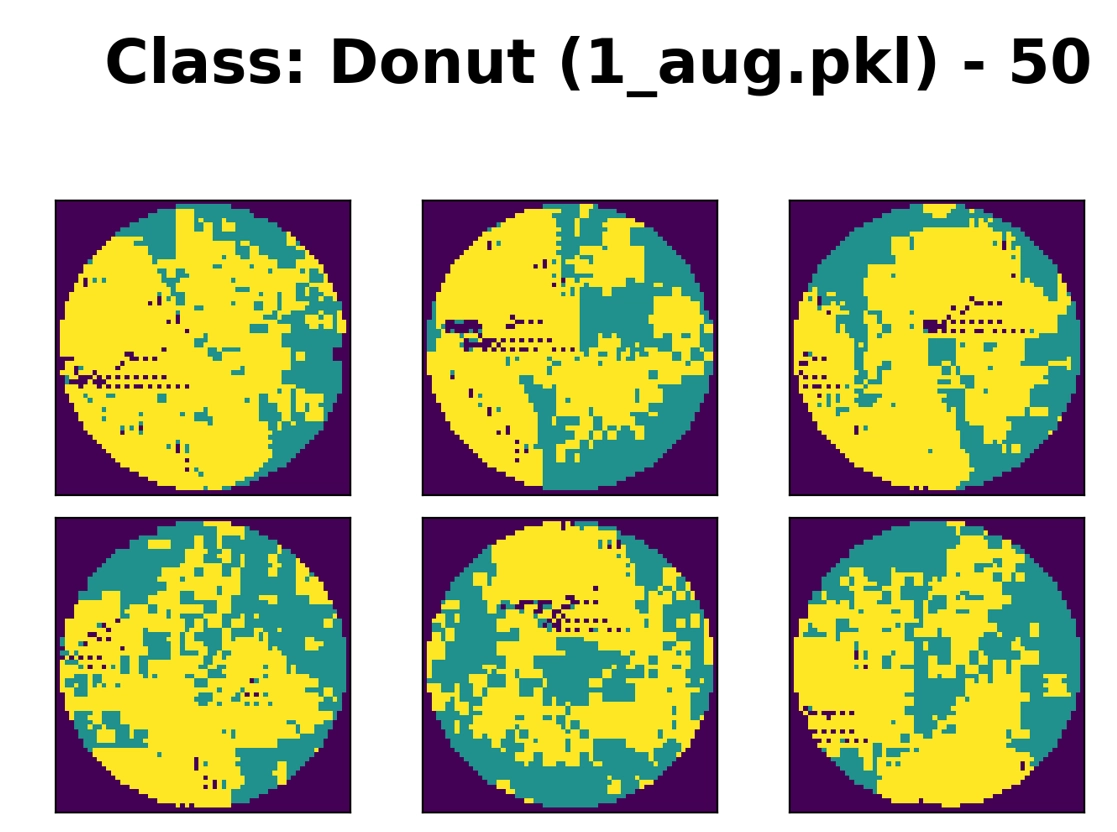
-> 문제발생. 도넛에 이상한 보라색(웨이퍼 바깥) 데이터가 들어갔음. 코드 수정 작업 필요.. 그리고 도넛 같이 생기지도 않았음. 전처리 과정을 다시 재검토 해야할 것 같다.